
Travail en cours, le 16 octobre 2009
Observons tout de suite que la première question à se poser n'est peut-être pas comment on crée un site. On pourrait commencer par en soulever bien d'autres, notamment : Pourquoi ? Eh bien non, « comment » est plus simple, et aidera déjà à trouver des réponses aux autres questions.
Un site, c'est au moins une page, c'est-à-dire, on l'a vu, un fichier HTML. Ce fichier s'appellera « index.html » et pas autrement (sauf indication expresse de l'hébergeur), et ce fichier se trouvera à la racine du site, c'est-à-dire au premier niveau.

Ce fichier s'affichera dès qu'on appellera l'adresse du site dans le navigateur, par exemple « machin.fr ».
Si le fichier ne s'appelait pas « index.html », il ne s'ouvrirait pas. Il s'afficherait dans la fenêtre du navigateur avec son icône et son nom, comme dans la fenêtre d'un dossier (mais il s'affiche cependant si l'on y clique dessus).
Ce fichier a une certaine importance, puisqu'il est l'entrée du site, donc la première image qu'on en verra, si l'on entre toutefois par l'entrée, et dans tous les cas, celle où l'on aura tendance à aller quand on cherche quelque chose. Ce fichier devra donc conduire vers les autres pages de notre site — s'il en a d'autres — ou vers ses autres départements — si c'est un grand site.
Il est en quelque sorte l'équivalent de l'éditorial et du sommaire pour un journal, de la préface et de la table des matières pour un livre. Un site peut toutefois ne contenir qu'une page. Dans ce cas, elle débutera par l'éditorial et le sommaire de son contenu.
Comment s'y prend-on pour réaliser une telle page ? Il y a deux méthodes.
La première consiste à l'écrire directement dans un éditeur de site wysiwyg (abréviation de what you see is what you get) qui nous permet de travailler le HTML comme il s'affiche dans la page du navigateur. Un tel programme est pour l'édition en ligne l'équivalent d'un logiciel de PAO pour l'imprimé. Il est seulement moins précis et contient moins d'outils pour la mise en page, pour la raison évidente que la page s'affichera sur d'autres machines et d'autres écrans et qu'elle doit donc conserver une certaine élasticité. Il existe de nombreux programmes, libres ou commerciaux, dont les plus connus sont Kompozer pour les premiers et Deamweaver pour les seconds.
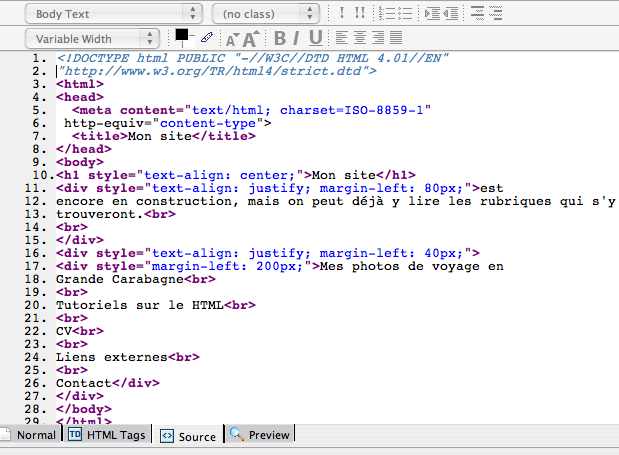
Cette méthode est la meilleure pour un débutant. En effet, ces logiciels permettent toujours d'afficher la page sous quatre formes : Normal (celle par défaut), Balises HTML, Code source et Aperçu. On peut naturellement travailler dans ces quatre formes d'affichage. Il est probable qu'au début seuls le premier et le dernier onglets seront utilisés.
Le premier onglet affiche la page avec des cadres invisibles (non plus cette fois des caractères). On ne les appellera pas cadre pour éviter une confusion (ce qu'on appelait « cadre » est aujourd'hui déconseillé dans les pages web, et l'on n'en reparlera plus), on dit des divisions.
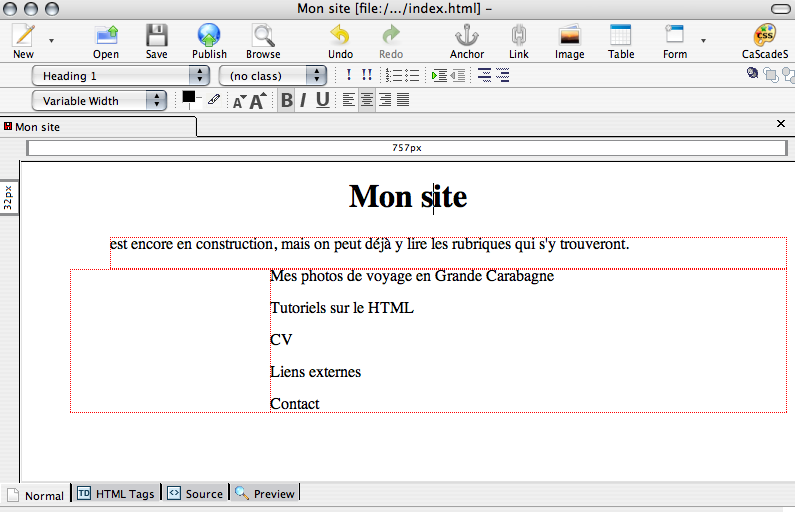
Le quatrième montre la page telle qu'elle apparaît dans un navigateur.
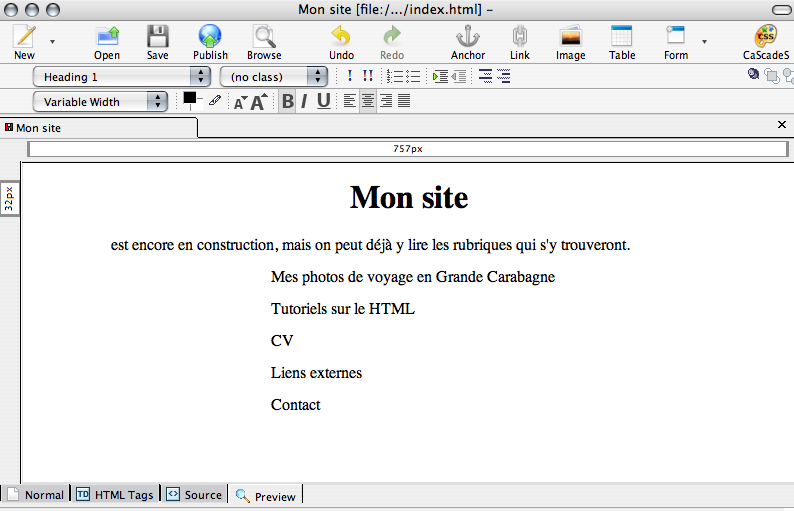
Les deux autres onglets sont quand même très intéressants pour le débutant. Le deuxième montre la page en affichant les balises qui la structurent.
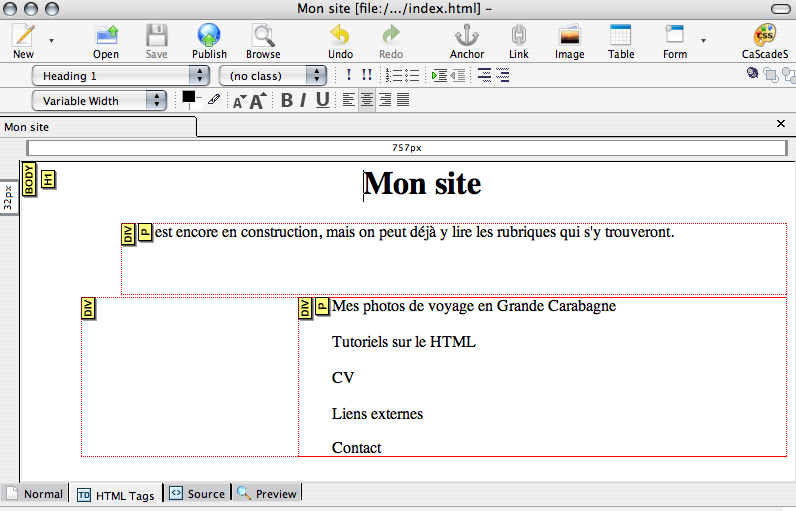
Au titre correspond la balise « H1 », c'est-à-dire l'en-tête (header) de niveau 1. Aux paragraphes correspond « P ». On distingue aussi les divisions par la balise « DIV ». Nous voyons distinctement les éléments qui structurent notre page.
Dans le troisième onglet nous pouvons lire le code. C'est évidemment inextricable au premier abord, même si le code est colorisé. C'est cependant très instructif, nous avons commencé à le voir dès la première partie.
(On remarquera que la barre d'outil de formatage en haut est grisée, car elle est naturellement devenue inutile.)
Nous pouvons décorer un peu plus cette page. Les fonds légèrement gris sont plus reposants pour la lecture à l'écran. C'est très simple avec le menu « couleur de fond ». Nous pouvons aussi changer la couleur des polices. Tout cela est facile mais pas très important en réalité.
Tout ce qu'on rajoute à du texte pour le décorer est comme pour la parole si l'on criait, et plus on crie, moins on se fait comprendre. Le marchand de rue crie, bien sûr, mais seulement pour attirer les clients, capter leur attention et leur asséner des messages très simples. « Trois pour le prix d'un ! » Si quelqu'un voit votre page, c'est qu'il y a déjà été attiré, ce n'est plus la peine de crier. Maintenant, libre à vous de placer des publicités sur votre page qui, pendant que vous parlez, crieront pour attirer le lecteur ailleurs.
Cette première méthode est la plus simple, la plus évidente, la plus souvent expliquée. Il suffit d'installer le logiciel et de se laisser guider par le menu d'aide. Elle a cependant un gros inconvénient si l'on veut faire davantage qu'une page d'accueil et quatre ou cinq autres petites : on doit tout prendre à zéro. Or dans la pratique ce que nous souhaitons mettre ne ligne est déjà tout fait et bien fait. Notre document est déjà structuré, illustré, et notre problème est de savoir seulement comment nous y prendre pour en faire le plus rapidement et le plus simplement possible une page web, voire un site entier.
Il suffit de l'exporter en HTML. L'exportation n'est pas non plus compliquée, comme nous avons commencé à le voir dès le début. On pourra s'en contenter si : on ne crée qu'un petit site de quelques pages ; on a utilisé son traitement de texte dans les règles de l'art ; on n'est pas trop exigeant sur le résultat.
Les difficultés s'accumuleront de toute manière au fil des mises-à-jour et de la croissance du site — car un site croît toujours et ne décroît jamais.
On doit savoir d'abord qu'il existe plusieurs versions du HTML (cinq plus les versions intermédiaires et des versions « transitionnelles »). Ceci ne doit quand même pas trop nous inquiéter. Les navigateurs sont très laxistes avec le code. C'est un peu comme l'orthographe du français, quelques fautes ne rendent pas un texte illisible. De plus, seul le programme lit le code, et non un lecteur humain ; en principe donc, personne ne le saura. Les pages sans faute sont extrêmement rares sur le web, même sur les sites où l'on s'attendrait à une autre rigueur, comme ceux des éditeurs de site. Toutefois, comme avec l'orthographe du français, on ne doit quand même pas exagérer.
Le plus grand nombre d'erreurs de code vient d'un mélange de balises propres à des versions différentes du HTML, et elles auront d'autant plus de chances de se produire qu'on se servira de plusieurs logiciels, ou encore qu'on fera des mises-à-jour de ses pages sur la longue durée, soit avec de nouveaux logiciels, soit avec de nouvelles versions successives des mêmes. Il est à peu près impossible de se contenter d'exporter à partir d'un traitement texte pour créer et gérer un site.
Pour être plus clair et plus précis, il est nécessaire d'aborder un cas concret. Le meilleur est d'éditer cet ouvrage lui même. Pour cela, il sera utile d'employer plusieurs logiciels. On exportera le texte à partir d'un traitement de texte. Open Office est une bonne solution. On utilisera aussi un éditeur de site. Kompozer, est un très bon choix. Ces deux programmes peuvent être suffisants, mais on peut en employer d'autres : un éditeur de texte, de préférence doté d'un correcteur de syntaxe ; peut-être un éditeur spécifique de CSS (feuilles de style) ; etc.
Il vaudra mieux commencer par accorder les deux programmes sur leur code. Par défaut, Open Office utilise du HTML 4 transitionnal. Ce n'est peut-être pas le choix optimal, mais il n'en laisse pas beaucoup d'autres et ce sera le meilleur dont on dispose, jusqu'à une prochaine version. Kompozer, lui, exporte par défaut en HTML 4 stric. Le plus simple serait alors de modifier les préférences et d'opter aussi pour du transitionnal.
Pourquoi va-t-on utiliser au moins ces deux logiciels. Le traitement de texte, c'est évident, sert à écrire et formater le texte, puis à l'exporter. L'éditeur de site sert, lui, à créer une matrice dans laquelle on exporte le texte, comme avec un logiciel de PAO pour l'édition sur papier.
Nous devrons d'abord déterminer en combien de pages nous exporterons le texte. Nous pouvons en effet faire un seul gros fichier HTML. Les liens internes pour naviguer entre la table et les chapitres seront alors essentiels.
Ce n'est toutefois pas très pratique de naviguer dans un gros document. La seule bonne raison que nous aurions de le faire est de permettre le téléchargement en un seul fichier (plus un dossier image). C'est aussi un bon choix pour sauvegarder et échanger des documents dans un format très portable. C'est cependant une mauvaise solution pour la lecture en ligne.
Si l'on découpe le texte, en devra définir en combien de parties. La question est alors de décider du nombre et de la taille de ces parties. Choisira-t-on le premier niveau, par chapitre, ou le second, par sous-chapitre, ou le troisième…?
Pour choisir, on doit se baser sur la difficulté du texte qu'on édite, l'effort et les capacités de lecture qu'on suppose du visiteur. Plus le texte s'adresse à un lecteur attentif, prêt à un effort et capable de le faire, plus il est préférable de présenter le texte sur des grandes pages. Plus le texte est facile à lire et contient des informations simples et peu liées entre elles, plus il est préférable de le découper en de nombreuses pages autonomes.
On se perd souvent plus dans un dédale de pages que dans la complexité intrinsèque d'un ouvrage, mais d'un autre côté, les pages trop longues découragent la lecture. L'évaluation n'est donc jamais simple. Il me semble que la division de cet ouvrage en quatre parties, plus la table, la préface, l'introduction et une annexe est raisonnable.
L'éditeur de site nous servira à dessiner l'apparence de ces pages et à en créer un modèle dans lequel nous importerons les chapitres.
Lorsque nous exportons un texte pour l'éditer en plusieurs parties, plusieurs possibilités nous sont offertes. Nous pouvons l'exporter intégralement et le découper après. Nous pouvons le découper d'abord en plusieurs fichiers que nous exportons séparément, nous pouvons enfin exporter séparément des sélections du texte.
Il n'est pas de solution qui soit absolument meilleure qu'une autre. Tout dépend d'abord des performances de nos programmes et de notre système. Tous les traitements de texte ne permettent pas d'exporter seulement une sélection. Tous dépend aussi des commodités de navigation et de sélection dans un document.
Le choix d'exporter le document entier en un seul fichier a l'avantage de pouvoir faire des corrections systématiques sur sa totalité en une seule fois. Par exemple, Open Office a tendance à utiliser dans les balises d'image (<img>) l'identifiant « name » (facultatif) à la place de « alt » (obligatoire) ; il est possible de faire un remplacement systématique sur tout le document en une seule fois.
Il est logique que toutes les pages aient la même présentation et que nous n'ayons pas à recommencer le même travail pour chacune. Dans notre traitement de texte, l'ouvrage a déjà une présentation soignée, mais elle est adaptée au papier et pas à l'écran.
La mise en page pour l'écran pose des problèmes très particuliers. Certains s'acharnent à ouvrir la fenêtre de leur navigateur sur toute la surface de leur grand écran, d'autres cherchent à lire sur celui de leur téléphone portable. Même dans des cas plus raisonnables, la différence entre des affichages de 800 ou de 1280 pixels ne sont pas identiques, surtout en tenant compte de la distance en centimètres, sur des écrans qui tendent à devenir à la fois plus grands pour les machines de bureau, et plus petits pour des ultra-portables.
Que se passe-t-il dès qu'on crée une nouvelle page dans un éditeur HTML ? Dans le volet « normal », rien de visible ; dans le volet « balises HTML », rien non plus puisqu'on n'y a encore rien rentré. Il en va bien autrement dans l'onglet « code source ».
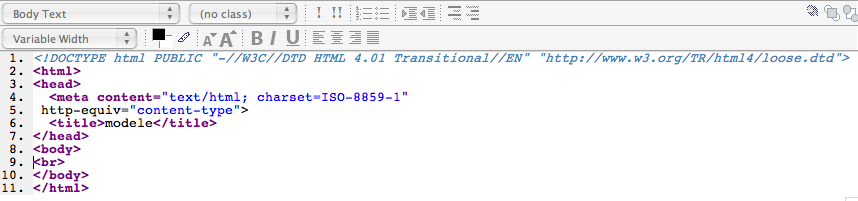
— Nous voyons d'abord le DDT et nous pouvons nous assurer qu'il est bien en HTML 4.01 Transitionnal :
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
— Puis nous voyons en dessous des enchâssements de balises. Tout y est enserré entre la balise ouvrante <html> et la balise fermante </html>. Nous y voyons comment fonctionnent toutes ces balises : elles s'appliquent à tout ce qu'elles enferment.
Notre page est en HTML mais nous aurions pu la faire en XHTML. La DDT aurait alors annoncé « XHTML 1 », et les balises auraient été <xhtml></xhtml>.
Entre cette paire de balises, on en trouve encore deux autres paires : <head></head> et <body></body>.
— Nous l'avons déjà vu, entre les deux dernières, <body></body>, nous avons tout ce qui est destiné à s'afficher dans la fenêtre du navigateur. Pour l'instant, il n'y a rien. (Sauf un saut de ligne, <br>.)
— Entre les balises <head></head>, se trouve le code à interpréter par des programmes. Nous y trouvons la paire <title></title> qui contient le titre de la page. Il est destiné à s'afficher dans la fenêtre du navigateur. Pour l'instant, dans la barre de la fenêtre de l'éditeur, c'est le nom du fichier qui est affiché : modele.html.
Nous préférons ne pas mettre d'accents dans les noms de fichiers, et n'utiliser que les caractères ASCII. Nous ferons bien aussi de proscrire les majuscules pour éviter toute erreur. En effet, les navigateurs ne sont pas sensibles à la casse en local, mais ils le deviennent en ligne, et cela génère souvent des erreurs.
— Nous avons aussi une balise META :
<meta content="text/html; charset=ISO-8859-1" http-equiv="content-type">
Il en existe bien d'autres plus ou moins indispensables, plus ou moins utile. On observera que ces balises-là ne vont pas par paires, et il en existe d'autre dans ce cas qui se placent dans le HEAD ou dans le BODY (comme le saut de ligne <br>).
Cette balise « charset » est la plus indispensable, Elle indique au navigateur avec quel jeu de caractères il doit afficher la page. S'il n'y en avait pas, il l'afficherait avec le jeu de caractères défini par défaut, et notre page ne pourrait être lue correctement que par ceux qui utilisent par défaut l'ISO-8859-1 sur leur système. Nous ignorerions donc une part importante des habitants de la planète, et notamment des francophones et gallicisants.
— Il en est qui peuvent toujours être utiles : <META name="date" content="nnnn-n-nn">, qui indique la date de création du fichier sous la forme « année-mois-jour ».
— D'autres le sont quelquefois : <META name="robots" content="noindex">. La balise « robot » indique aux moteurs de recherche ce qu'ils doivent faire de notre page. La variable « noindex » (no index) leur demande de ne pas l'indexer. C'est très pratique pour un travail qui, sans être secret, ne concerne que des gens précis qui en connaissent l'URL, ou qui est à un stade d'évaluation. L'autre valeur pourrait être : « index ».
Un éditeur HTML devrait nous permettre d'ajouter toutes les META qu'on souhaite, mais il ne faut quand même pas trop y compter.
Bien d'autres balises peuvent se mettre encore dans le HEAD.
Toutes nos pages devront donc avoir :
— Une même couleur de fond.
— Une même en-tête. Celle-ci devrait au moins contenir le nom de l'ouvrage, celui de l'auteur, un lien vers l'entrée du site qui l'héberge ; peut-être une adresse pour contacter l'auteur, une icône, un logo…
— Un pied de page, indiquant peut-être la date, le copyright et/ou la licence, etc.
— Des marges, car il est pénible de lire un texte qui va d'un bord à l'autre de la fenêtre.
— De quoi naviguer d'une page à l'autre.
Pour structurer cela, on peut utiliser des tableaux. Il vaudrait mieux cependant utiliser des blocs : ce serait plus simple si l'on voulait ensuite faire le mouvement inverse de la page web au traitement de texte. On utilisera pour cette fois des tableaux malgré tout, car s'il est plus facile de gérer des blocs directement avec du code, on ne le connaît pas encore. Il est au contraire beaucoup plus facile de créer les tableaux sans connaître de code, mais on devra savoir qu'on se compliquera la vie pour rééditer le HTML sur un traitement de texte.
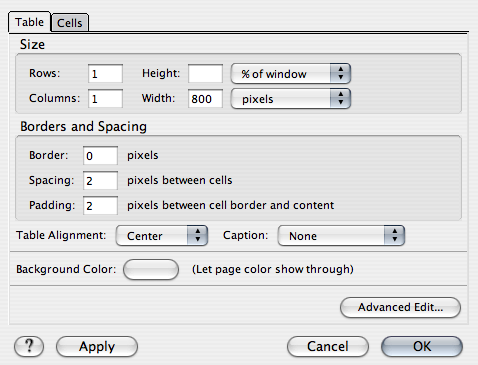
On fera donc trois tableaux. Un pour l'en-tête, avec au moins deux colonnes si l'on veut y placer un logo.
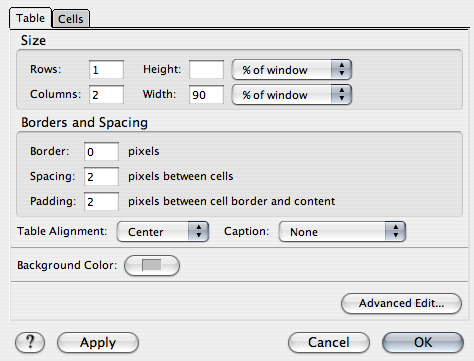
On lui donnera pour valeur 90% de la taille de la fenêtre par exemple. Pour la bordure, on prendra 0 pixels, puisque le tableau sert seulement à structurer le contenu et ne doit pas être vu en tant que tel. Et on le centrera.
Pour les cellules, on donnera par exemple 120 pixels pour la première colonne qui devra contenir un logo.
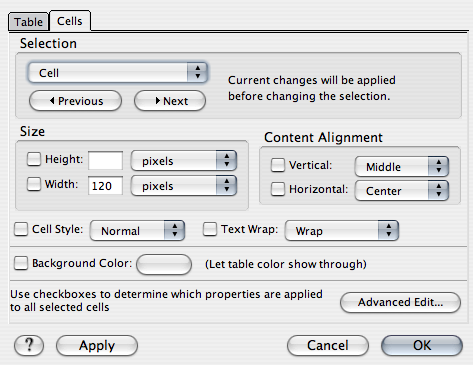
On en fera un autre pour le texte, avec une seule colonne, une seule rangée et une largeur définie, pour que les lignes ne s'étalent pas trop sur un grand écran. On lui donnera une largeur de 800 pixels, pour que le texte entre bien dans la fenêtre sur un petit écran. On le centrera aussi.
Puis on en fera un troisième de même pour le pied de page.
Notre modèle devrait donc avoir cette apparence dans la fenêtre de Kompozer, avec l'onglet « normal », après qu'on ait mis un gris léger en fond de page, et peut-être un plus soutenu comme couleur de fond du premier tableau.
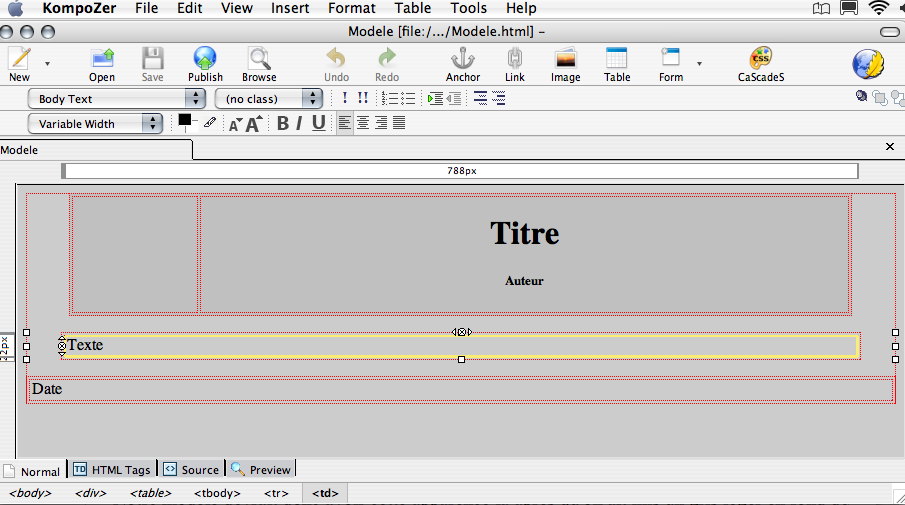
L'intérêt pour un débutant de travailler avec un tel logiciel est qu'il lui permet de voir affichés les cadres invisibles de tous les objets qu'il rajoute. Dans la fenêtre d'un navigateur, il ne les verrait pas plus que dans l'onglet « Aperçu ».
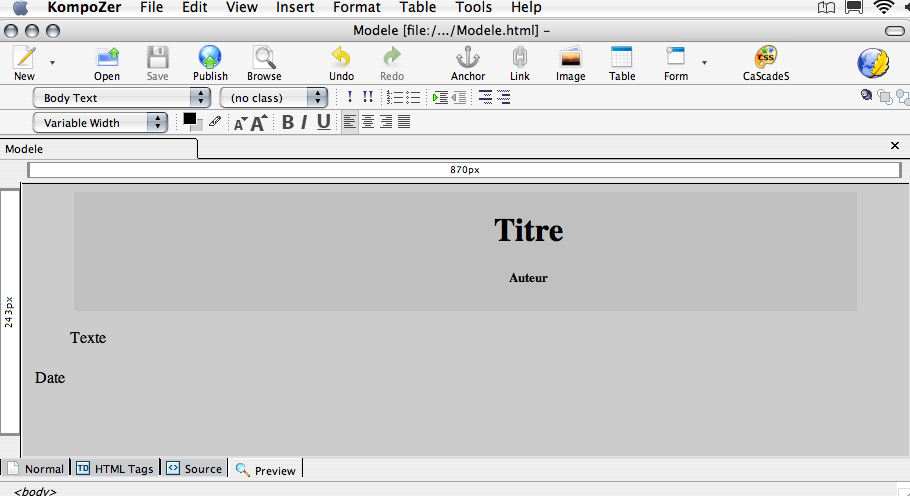
Mais en code source, ce serait un peu inextricable :

Maintenant que nous avons la matrice de nos pages, et que nous pouvons la parfaire davantage, nous devons nous occuper du fichier de leur contenu que nous avons exporté en HTML. (Nous aurions pu l'exporté aussi en autant de fichiers.)
Ouvrons maintenant ce fichier « txt.html » et voyons ce qu'il contient. Affichons-le dans le volet « Code HTML » de Kompozer. Nous voyons tout de suite que la partie HEAD est bien plus importante que sur notre modèle.
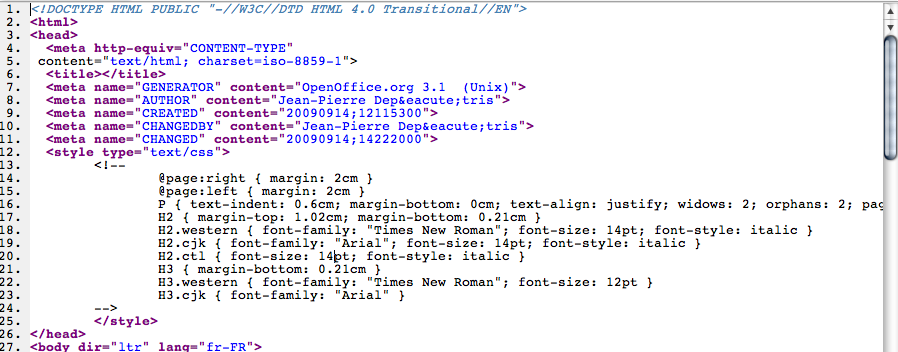
Nous allons y chercher ce qui nous intéresse pour l'exploiter dans notre fichier « modele ».
Le DDT est en principe le même ; la META « charset », aussi. Quelques autres META peuvent nous être utiles et nous les copierons dans le HEAD de notre modèle. (Nous remarquons cependant qu'Open Office exporte en HTML 4.0, et Kompozer en, 4.01.)
On voit une nouvelle balise qui nous intéresse davantage : <style></style>. Nous pouvons immédiatement en copier le contenu dans un éditeur de texte. Nous l'enregistrerons au premier niveau du site sous le nom, par exemple, de « methode.css » (sans majuscule toujours). Nous nous en occuperons plus tard.

Voyons maintenant comment est la balise <body>.
Quelles que soient les qualités d'un programme, il ne lit pas dans nos pensées. Soit nous pouvons lui spécifier exactement ce que nous attendons, et cela s'appelle programmer, soit il accomplit bêtement les tâches pour lesquelles il est fait. Nous serons donc toujours partiellement déçu.
Nous savons déjà qu'il n'y a pas d'identifiant « alt » dans les balises d'image. Si l'on est scrupuleux, on les corrigera (fonction « Remplacer »). L'identifiant « alt » indique le texte qui devra être lu par un programme de reconnaissance vocale qu'utilisent les malvoyants. Pour l'occasion, elle ne leur apprendra guère plus qu'il se trouve là une image qu'ils ne peuvent pas voir ; ce qui est déjà quelque chose. Si encore une fois on est scrupuleux, on renseignera davantage les champs.
Nous trouvons aussi beaucoup de balises <font></font> qui ne devraient pas se trouver dans du HTML 4, et c'est pourquoi nous avons choisi « Transitionnal ». Si l'on est très scrupuleux, on les supprimera aussi ; ça ne devrait en principe rien changer, dans la mesure où tout le texte est composé dans la même police et que tous les autres enrichissements dont déjà indiqués autrement.
Nous trouverons encore, tout en bas, Une balise <div type="FOOTER"> :

C'est une indication pour imprimer le pied de page, qui n'a pas une réelle utilité dans une page web, et nous la supprimons aussi.
Ce devrait être à peu près tout, si le texte a été composé avec Open Office dans les règles de l'art. Voyons ce que donne le fichier dans le volet « Aperçu ».
Si la présentation ne correspond pas bien à ce que nous souhaitons, nous ne nous en soucierons pas trop. Nous pourrons la corriger plus tard autrement avec la feuille de style. Nous noterons simplement les principaux détails qui ne nous conviennent pas.
Les images sont alignées à gauche et non centrées, les paragraphes ont trop d'espace entre eux, etc.
Les CSS sont un langage de mise en forme des fichiers HTML. La CSS de notre page est déjà toute faite : nous l'avons déjà trouvée entre les balises <style></style>. Nous allons apprendre d'abord succinctement à la lire, et nous pourrons commencer à la corriger.

Les deux premières lignes concernent les marges de la page si on l'imprime. Ces indications d'impression, comme les dernières balises de la partie BODY, ne sont pas très judicieux pour du HTML, et même déconseillées. Si l'on tient à la mise en page sur papier, il vaut mieux utiliser un autre format comme le PDF. Si l'on souhaite pouvoir modifier le document, on utilisera alors un format comme le XML, TeX, ou au pis aller du RTF. Le principal avantage du HTML est de permettre de modifier autant qu'on veut la mise en page sans que cela ne corrompe aucune propriété du texte et de sa structure. On pourra donc effacer ces deux premières lignes.
La troisième ligne concerne les paragraphes.
P { text-indent: 0.6cm; margin-bottom: 0cm; text-align: justify; widows: 2; orphans: 2; page-break-before: auto }
P désigne le sélecteur, ici les paragraphes. Entre les accolades sont des déclarations qui décrivent comment le style est appliqué. La déclaration a deux parties : la propriété (text-indent) et la valeur (0.6 cm), dans ce cas, elle indique un alinéa de 0,6 centimètres. La deuxième déclaration justifie le texte. Les deux suivantes interdisent les orphelines en fin ou en début de page. C'est tout.
Les quatre lignes suivantes concernent les titres de deuxième niveau. La première, H2, concerne tous ces titres. La deuxième, ne s'applique qu'aux titres suivis de class="western" au sein de la même balise (<H2 class="wester">. Le principe est le même pour les deux suivantes.
H2 { margin-top: 1.02cm; margin-bottom: 0.21cm }
H2.western { font-family: "Times New Roman"; font-size: 14pt; font-style: italic }
H2.cjk { font-family: "Arial"; font-size: 14pt; font-style: italic }
H2.ctl { font-size: 14pt; font-style: italic }
On comprend la suite.
On retiendra quelques points à ne jamais négliger : Dans un fichier HTML, la casse du code n'a aucune importance ; dans les CSS, non. On doit être attentif aux majuscules et aux minuscules. À l'inverse, les espaces autour des ponctuations (“{” “;” “:”) n'ont aucune importance. L'ordre des déclarations n'a pas non plus d'importance.
Le contenu de cette feuille de style est insuffisant, et il n'est pas étonnant que la présentation nous déçoive.
Tout d'abord, nous avons choisi une seule et même police pour tout le document et elle n'est indiquée que dans une seule déclaration : font-family: "Times New Roman".
La taille de la police n'est pas toujours indiquée, et quand c'est le cas, elle l'est en points, c'est-à-dire en mesures absolues. Les valeurs absolues possibles dans une CSS sont les millimètres (mm), les centimètres (cm), les pouces (in), les points (pt) et les picas (pc). Il est préférables d'utiliser des valeurs relatives aux écrans : em (hauteur des caractères), ex (hauteur de la lettre x), px (pixel). Il vaut mieux encore utiliser des indications plus relatives encore : medium, small, large, et x-small, xx-small, x-large, xx-large ; ou encore smaller, larger.
Dans le sélecteur P nous lisons :margin-bottom: 0cm. Cela signifie qu'il n'y a pas d'espace après le paragraphe ; comme les paragraphes sont cependant trop espacés, c'est qu'il y en devant. Nous allons donc copier et coller cette déclaration et changer bottom par top : margin-top: 0cm. Ces deux déclarations devraient faire qu'il n'y ait plus d'espace entre deux paragraphes. (Nous pourrions aussi changer partout cm par px, ce qui en l'occurrence n'a aucune importance.)
Voilà à quoi devrait ressembler finalement notre déclaration de paragraphe :
P {font-family: "Times New Roman": font-size: medium ; text-indent: 25px; margin-bottom: 0px; margin-top: 0px; text-align: justify; widows: 2; orphans: 2; page-break-before: auto }
Nous pouvons continuer pour tous les sélecteurs jusqu'à ce que la présentation nous satisfasse complètement, ou du moins suffisamment. Ce que nous sommes en train de faire n'est qu'un exercice pour comprendre le principe et savoir l'appliquer. Nous allons ensuite recommencer plus rigoureusement.
Quand nous somme satisfait, nous copions encore une fois le nouveau contenu de la balise STYLE, et nous allons le coller à la place de celui de notre fichier « methode.css ».
Nous n'y ajoutons rien d'autre. Il n'a besoin d'aucune sorte de déclaration.
Nous avons maintenant un fichier CSS externe qui est très pratique si nous voulons apporter des modifications en une seule fois sur toutes nos pages.
Avant cela, pour que ce fichier puisse nous servir, il doit pouvoir être lu dans la page HTML de notre modèle. Nous allons donc créer un lien dans celle-ci.
Nous commençons par ouvrir le fichier « modele.html ». Nous cherchons dans le menu outil l'éditeur de CSS, nous sélectionnons « Linked Stylesheet » dans le menu déroulant du bouton à l'extrême gauche, et nous sélectionnons notre fichier à l'aide du bouton « Choose File ».
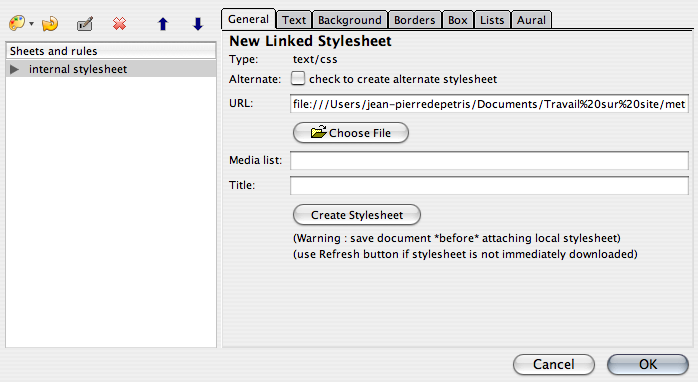
Nous observons le changement dans le volet code HTML.

Maintenant, nous pouvons créer les diverses pages de notre site et y coller les différentes parties de notre fichier « txt.html ». Créons notre premier fichier par le menu « enregistrer sous » et appelons-le « methode_1.html ».
Ouvrons aussi notre fichier « txt.html » et sélectionnons-y le passage que nous souhaitons coller. Copions-le et revenons à la page « methode_1.html ». Nous plaçons notre curseur dans le tableau du milieu et nous y collerons le texte. Le résultat devrait correspondre à nos attentes.
Il n'y a aucune raison à priori de se préoccuper du code si des programmes sont là pour l'écrire à notre place. Cependant, à l'usage, il est souvent plus simple de l'entrer à la main que de se lancer dans un labyrinthe de boutons, de fenêtres et de menus déroulants, qui, la plupart du temps ne nous satisfont même pas pleinement. De plus, au fur et à mesure que nous utilisons du code, nous le manipulons plus facilement et plus rapidement. Nous disposons aussi d'éditeurs de texte qui peuvent faire pour nous la moitié du chemin.
Quel que soit le travail que nous effectuons avec un programme, il devra bien, à un moment ou à un autre, s'en émanciper. Il devra sortir du programme, de l'ordinateur, du système. Sinon, c'est comme si l'on n'avait rien fait. Le temps seul d'ailleurs nous y contraint, quand le programme devient obsolète, ce qui arrive assez vite.
Les programmes qui doivent nous simplifier la vie en écrivant le code à notre place, n'en demandent pas moins un certain apprentissage. Il est souvent nécessaire de le reprendre à zéro quand nous en changeons. Les langages, eux, évoluent de façon plus modulaire et ne demandent presque jamais de tout recommencer.
On l'a vu avec les jeux de caractères : l'ISO n'annule pas l'ASCII ; ni l'UFT, l'ISO. Le HTML 4 ne nous fait pas oublier le 3, et les CSS ne rendent pas obsolète le HTML. On n'acquiert rien en vain, et les nouvelles briques se placent sur les anciennes.
Tous ceux qui ont une pratique soutenue de l'écrit savent, même s'ils ne songent pas à le dire, que le plus dur n'est pas d'écrire, mais de s'y retrouver dans un nombre toujours croissant de pages qui deviennent au fil des temps une jungle inextricable. En réalité, cette prolifération est cannibale ; elle revient à un effacement. Même ceux qui ne pratiquent pas si intensivement l'écriture, ont pu expérimenter que cette auto-destruction de l'écrit surgit plus rapidement qu'on s'y attend, et de telle sorte qu'elle nous surprend toujours. Dans l'action, nous surestimons toujours notre capacité à nous y retrouver dans des documents, et nous tendons à oublier l'exacte durée du procès d'écriture — généralement assez longue.
Bien souvent, un ouvrage échoue à voir le jour car il est devenu inexploitable bien avant d'être achevé. Que les documents soient physiques ou numériques n'y change pas grand chose. Créer et entretenir un site est une excellente discipline pour apprendre à s'y retrouver. À la fois, elle nous impose immédiatement un ordre rigoureux pour lier entre eux les éléments de notre travail, et maintient notre attention sur le procès à long terme par les liens externes. Il est donc important de bien organiser ses fichiers et ses dossiers qui vont très vite se multiplier.
Nous aurons créé un dossier pour notre ouvrage, qui contenait déjà notre modèle de page (modele.html). À l'aide de celui-ci, nous avons créé les autres pages, peut-être index.html ; intro.html ; part1.html ; part2.html ; part3.html ; part4.html ; annexe.html…
Nous avons exporté le texte entier en HTML, et nous l'avons enregistré sous le nom txt.html. Pendant cette opération un nombre considérable de fichiers d'images ont été générés. Tout laisser dans le même dossier est problématique ; on ne va plus s'y retrouver. Une bonne idée serait de placer tous nos fichiers d'images dans un nouveau dossier « images », à la racine du premier. Seulement dans ce cas, tous les liens seront perdus. À la place de nos images, ne s'afficheront plus que des cadres vides.
Pour ranger nos dossiers et nos fichiers qui se multiplient si vite, nous avons besoin d'un éditeur de texte qui sache renommer et déplacer des fichiers et des dossiers tout en corrigeant automatiquement les liens entre eux. Cela, Kompozer ne sait pas le faire. On devrait cependant pouvoir trouver ce genre d'outil pour n'importe quel système, gratuit ou payant.
À défaut d'un tel logiciel, on peut toujours faire un remplacement automatique.
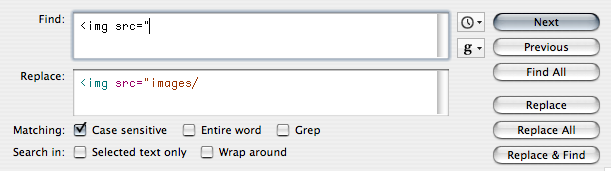
Il suffira d'appuyer sur le bouton « Replace All » pour que tous les liens soient mis à jour. L'avantage est ici évident de réaliser cette opération avant, sur un seul gros fichier qui contient le texte intégral.
Nous avons formaté les pages à l'aide de tableaux. Le procédé est plus simple quand on utilise un éditeur en mode wysiwyg, mais il génère des complications dans le code source, et dans l'exploitation du fichier si l'on souhaite le convertir plus tard en d'autres formats. Il est plus judicieux d'utiliser la balise <div>.
Il nous suffit de trois ou quatre divisions : haut, corps, pied, et peut-être logo :
<div class="haut"></div>
<div class="corps"></div>
<div class="pied"></div>
<div class="logo"></div>
Voilà donc à quoi ressemblerait notre modèle :
<body>
<div class="logo"></div>
<div class="haut">
<H1>Titre</H1>
<H5>Auteur</H5>
</div>
<div class="corps">
</div>
<div class="pied">
<P>Date</P>
</div>
</body>
Le code est tellement limpide qu'un débutant saurait le lire même s'il n'est pas colorisé. On peut encore y ajouter des annotations personnelles pour s'y retrouver plus facilement. Pour les rendre invisibles, on les écrit entre « <!-- » et « --> ».
<body>
<div class="logo"></div>
<div class="haut">
<H1>Titre</H1>
<H5>Auteur</H5>
</div>
<!-- fin du haut de page -->
<div class="corps">
<!-- Coller ici le corps du texte -->
</div>
<!-- Pied de page-->
<div class="pied">
<P>Date</P>
</div>
</body>
Voilà, tout est fait sur le modèle HTML. Il ne reste plus qu'à faire la présentation sur une feuille de style. Nous avons deux possibilités : soit nous complétons la feuille de style que nous avons déjà, soit nous en créons une seconde.
Il n'y a pas de limite au nombre feuilles de style qui peuvent être associées à une page HTML. Si celle que nous avons déjà faite nous convient pour le corps du texte, il est préférable d'en créer une autre pour la mise en forme. Il sera plus commode alors de tester les résultats, ou d'apporter à tout moment, même bien plus tard, des modifications sur l'ensemble des pages. On trouvera plus facilement les sélecteurs et leurs déclarations.
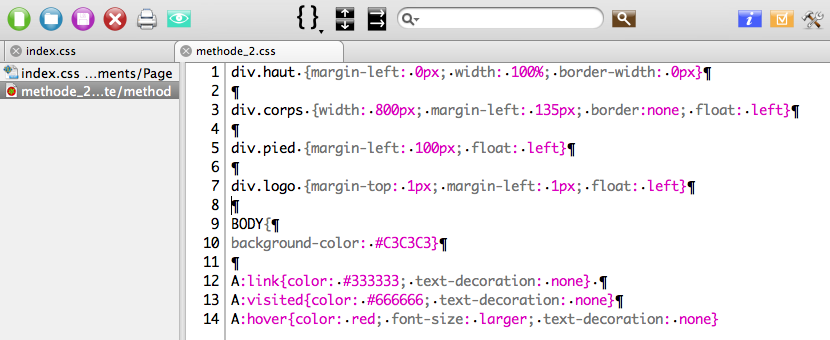
Cette feuille de style concernera donc les sélecteurs DIV. Nous pouvons ajouter aux quatre sélecteurs un autre générique pour toutes les balises DIV, qui déclarera, une fois pour toutes, les caractères communs à tous les autres, par exemple les marges de la page.
div.{
}
div.logo {
}
div.haut {
}
div.corps {
}
div.pied {
}
Si nous avons mémorisé la syntaxe, il n'est pas très difficile d'entrer à la main le contenu. Il est toutefois difficile de la mémoriser. En effet, le principal intérêt d'une CSS externe est de pouvoir être utilisée avec de nombreuses pages HTML. On a dont d'autant moins l'occasion de manipuler son code. Rien n'est plus simple non plus que de copier un fichier CSS d'un dossier à l'autre, dans lequel on n'aura la plupart du temps rien à changer.
C'est pourquoi, même quelqu'un qui édite très fréquemment du HTML trouve très peu l'occasion d'écrire du code CSS. Tout au plus, il modifiera quelques valeurs, mais ne retiendra pas le lexique et la syntaxe exacte, aussi simple qu'elle soit en réalité. Heureusement, beaucoup d'éditeurs de texte peuvent écrire le code à sa place. Soit qu'ils possèdent un outil pour éditer des feuilles de style, soit qu'ils sont entièrement dédiés à leur édition.
On va donc cette fois encore lier la seconde CSS dans le fichier « methode.html ». On commencera, dans la section HEAD, par copier et coller notre lien avec la première feuille de style, et on modifiera la seconde occurrence de « methode.css » en « methode2.css »..

Pendant que nous y sommes, nous pouvons ajouter à notre seconde feuille de style des indications pour les couleurs de fond (BODY { background-color: #C3C3C3}) et pour les liens (A:link : liens ; A:visited ; liens visités ; A:hover ; liens survolés).
Avant d'en arriver là, nous aurions dû nous occuper des moyens de navigation. Pour passer d'une page à l'autre, voire à une division d'une même page, nous devons leur donner des liens.
Le plus simple, serait de créer une table des matières, peut-être dans le fichier « index.html », peut-être sur une page spéciale, ou au moins chaque nom de chapitre en ouvrirait la page. Il est facile d'éditer des liens à l'aide du bouton de la barre d'outils de Kompozer ou de tout autre éditeur.
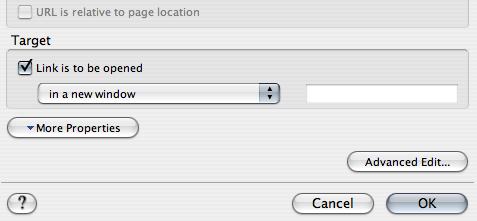
Il est alors judicieux de faire s'afficher la page dans un nouvel onglet, grâce à la valeur « target="_blank" ». On pourra ainsi revenir aisément au plan qui restera ouvert.
Il peut-être utile aussi de créer des cibles, ou ancres, dans le document, qui faciliteront la navigation en ouvrant la page à la hauteur du paragraphe recherché.
Il n'est pas très difficile d'entrer tous ces codes à la main. Toutes les balises de liens et d'ancres sont de structure <a></a>.
Les balises de liens s'écrivent selon la syntaxe <a href="adresse"></a>.
Quand le lien est dans le même dossier, elle s'écrit :
<a href="nom_du_fichier.html"></a>.
Si le lien va dans un autre dossier :
<a href="nom_du_dossier/nom_du_fichier.html"></a>
S'il y a plusieurs sous-dossier :
<a href="dossier_1/dossier2/nom_du_fichier.html"></a>
Si le fichier est dans un autre dossier :
<a href="../nom_du_dossier/nom_du_fichier.html"></a>
<a href="../../dossier/nom_du_fichier.html"></a>
…
Si le fichier est distant, on écrit son URL :
<a href="http://Nom_du_site.com/nom_du_dossier/nom_du_fichier.html"></a>
Les balises d'ancres s'écrivent selon la st-yntaxe <a name="nom_de_la_cible"></a>.
La syntaxe du lien pointant sur la cible s'écrit en ajoutant au lien le nom de la cible précédé d'un dièse :
<a href="nom_du_fichier.html#nom_de_la_cible"></a>.
Le lien avec le code pour ouvrir dans une nouvelle fenêtre s'écrit :
<a href="nom_du_fichier.html#nom_de_la_cible" target="_blank"></a>.

On utilisera le même principe pour naviguer d'une page à l'autre. Dans la mesure où le texte peut toujours être imprimé ou importé, le plus discret et le plus simple sera toujours le mieux. La seule suite des caractères « -> » est très bien
On peut à la rigueur faire s'afficher dans une bulle les mots « Page suivante ». La syntaxe est : <a href="adresse du fichier" title="Page suivante"></a>
On peut créer les liens déjà dans le traitement de teste, à condition du moins que les pages (ou les ancres) existent déjà, même si elles sont encore vides, ou qu'on ait déjà un nom à leur donner. Ils peuvent alors être exportés en HTML et en PDF.
On n'écrit pas avec un éditeur de pages web ni l'on ne gère un site avec un traitement de texte. C'est là qu'est toute la difficulté de l'édition en ligne. On doit donc se donner les moyens de passer alternativement de l'un à l'autre sans que le texte se corrompe. On doit aussi pouvoir changer d'éditeur et de traitement de texte sans provoquer de catastrophes, et être capable au besoin de coopérer sur de mêmes documents en permettant à chacun de travailler selon ses habitudes et avec ses outils familiers. Pour parvenir à cela, on doit s'en tenir à quelques règles bien précises.
- Veiller au code source : Si l'on insère dans un modèle un texte exporté en HTML, les deux fichiers devront être encodés dans la même version de HTML, de préférence une déclinaison de la version 4 qui gère les CSS, en attendant la 5.
- Ils devront aussi avoir le même encodage de caractères : ISO ou UFT. Si le texte inséré est en ISO et le doctype en UFT, ce n'est pas grave, le navigateur interprètera très bien le texte. Si à l'inverse le texte inséré est en UFT et le doctype en ISO, l'affichage sera selon les langues défectueux ou illisible. (C'est pourquoi il est plus sûr d'exporter les textes en ISO. Le réglage se fait par les préférences du programme.)
- Veiller à la préservation des styles. Le texte exporté en HTML ne devrait comporter à peu près que des balises de titre (H1, H2, etc.) de paragraphe (P), ou de listes (LI) ; un minimum de classes (CLASS) ou de pseudo-classes (ID) ; un minimum de balises SPAN. Il est alors plus facile de moduler la présentation par des feuilles de style externes (CSS).
Le code exporté est d'autant plus propre que le texte a été saisi correctement : pas de sauts de ligne vides, pas de tabulations inutiles, etc. Exporter ses textes en HTML et en vérifier le code est une excellente façon d'apprendre à bien utiliser son traitement de texte.
On verra au chapitre suivant comment nettoyer le code source.
Il importe d'abord de comprendre la syntaxe des CSS. Elle se construit sur ce modèle :
Sélecteur { propriété 1: valeur 1 ; propriété 2: valeur 2 }
Exemple: p { font-size: medium ; color: black }
Les sélecteurs peuvent avoir des attributs :
Sélecteur.attribut { propriété 1: valeur 1 ; propriété 2: valeur 2 }
Exemple : p.note { font-size: medium ; color: black }
Les CSS peuvent être locales, globales ou externes :
Locales, elles sont insérées dans le code source. Par exemple :
<p style="font-size: small; color: black"></p>
Un éditeur de page web utilise par défaut des CSS locales.
Globales, les déclarations applicables au document entier sont définies dans la tête de la page entre les balises <style> et </style>, au milieu des balises <HEAD></HEAD>. C'est ainsi qu'elles sont exportées du traitement de texte comme on l'a vu plus haut.
Externes, elles sont sur des fichiers distincts, comme on l'a vu aussi. Ceux-ci sont liés au fichier HTML par les balises à l'intérieur du HEAD : <link rel="stylesheet" href:"nom_du_fichier.css" type="text/css">. Il existe des éditeurs de feuilles de style externes, et les éditeurs de page web ont souvent un module interne pour cela.
Un fichier HTML peut avoir tout à la fois des CSS locales, globales et externes. Dans le cas de conflits, les CSS locales sont prééminentes sur les globales, et les globales sur les externes.
Les sélecteurs peuvent être la plupart des éléments du code HTML : p (paragraphes), h1, h2… (les divers niveaux de titre), li (listes), et aussi les barres horizontales (hr), les tableaux, leurs colonnes, leurs rangées et leurs cellules, les liens, actifs ou visités (a-link, a-hover, a-visited), les divisions (div)… et même la page entière (body).
On peut donner des attributs différents à un même sélecteur, par exemple un paragraphe de notes où l'on souhaitera que les caractères soient plus petits. On l'écrira ainsi dans la page HTML :
<p class="notes"></p>
et dans la CSS externe :
p.notes { font-size: smaller }
On peut souhaiter avoir des titres et des sous-titres dans des notes qui soient tous plus petits. Dans ce cas, on écrira ainsi dans la page HTML :
<p class="notes"></p>
<h1 class="notes"></p>
<h2 class="notes"></p>
Dans la CSS on pourra utiliser une notation générique d'attribut qui évitera d'inscrire autant de fois le sélecteur :
.notes { font-size: smaller }
L'attribut ID s'écrit de la même façon que CLASS dans le HTML : <p id="cit"></p>. Dans les CSS, il est indiqué par un dièse :
p#cit { font-style: italic }
#cit { font-style: italic }
S'il y a conflit entre les attributs et les sélecteurs, ID a la prédominance sur CLASS qui a la prédominance sur le sélecteur.
La balise SPAN a la prédominance sur tous les autres sélecteurs et attributs. Elle s'utilise ainsi et seulement sous forme locale :
<p>Corps de texte <span style="font-style: italic">passage en italique</span> suite du texte.</p>
On trouvera en ligne toutes les ressources pour aller plus loin.
Certaines unités correspondent à l'affichage fluide de l'écran, les autres à l'impression fixe sur papier, nous les disons relatives ou absolues.
| nom de l'unité | abréviation | définition | Valeur |
|---|---|---|---|
| empâtement | em | L'épaisseur de trait d'un caractère | relative |
| ex | ex | La largeur de la lettre x dans une police | relative |
| pica | pc | 1 pica fait 12 points | absolue |
| point | pt | 1/72 de pouce | absolue |
| pixel | px | un point sur un écran | relative |
| millimètre | mm | unité d'impression | absolue |
| centimètre | cm | unité d'impression | absolue |
| pouce | in | unité d'impression | absolue |
Les feuilles de style permettent d'utiliser toutes ces valeurs pour la taille des caractères (font-size) ou pour définir la taille d'éléments comme les marges, les bordures, etc.
Pour les caractères, il est préférable d'utiliser des valeurs plus relatives encore :
On peut donner à la propriété "font-size" : xx-small, x-small, small, medium, large, x-large, xx-large.
On peut encore utiliser les valeurs smaller et larger. Elles réduisent ou grossissent respectivement la taille des caractères d'un degré par rapport à ceux qui les entourent.
Pour élargir ce choix, on peut combiner la taille avec la graisse (font-weight). Quatre valeurs sont utilisables: normal, bold, bolder, leighter.
La graisse des caractères peut être encore définie plus finement par des nombres : 100, 200, 300, 400, 500, 600, 700, 800, 900. 400 est équivalent à normal, 700 à bold.
Il est judicieux d'utiliser les premières valeurs du tableau, « em » (épaisseur de trait d'un caractère) ou « ex » (largeur de la lettre x dans une police), pour définir les tailles d'à-peu-près tous les sélecteurs. Si le visiteur grossit ou réduit les caractères de la page web, la taille de tous les autres éléments seront alors changés en proportion.
La construction qui suit permettra d'obtenir des paragraphes dont les lignes contiendront à-peu-près le même nombre de caractères quel que soit l'affichage :
Fichier HTML : <div class="corps"><p>…</p></div>
Fichier CSS : div.corps { width: 40em }
Les couleurs peuvent être notées sur les feuilles de style par leur code hexadécimal, par leur nom (en anglais) ou par une notation en RGB (trichromie : rouge, jaune, bleu). Avec un peu d'habitude, cette dernière est plus intuitive pour trouver une couleur en entrant sa valeur.
Par exemple, la couleur "whitesmoke" (#f5f5f5) s'écrit ainsi : rgb(245, 245, 245). Les mêmes valeurs pourraient être données en pourcentage : rgb(96%, 96%,96%).

Si l'on utilise pleinement les ressources des CSS externes, on préfèrera avoir des blocs très simples avec des sélecteurs sans attributs (<p> et non <p class="xxx">). Si l'on veut diviser sa page, on utilisera plutôt des balises <div> (<div class="header"> ; <div class="corps"> ; <div class="note">...) auxquelles on attribuera, peut-être sur une feuille de style distincte, des propriétés et des valeurs (width ; font-size: smaller ; etc.)
La plupart des traitements de texte ne permettent pas d'exporter un tel code. Il en existe cependant qui offrent la possibilité d'exporter en HTML sans mise en forme, comme Bean pour Mac OS.

TextEdit et Itext sur Mac OS offrent dans les préférences d'opter pour l'exportation sans feuille de style, et l'on devrait pouvoir en trouver de semblables pour les autres systèmes, mais on risque de voir seulement remplacées les balises de CSS par celles d'un HTML obsolète.
Dans le meilleur des cas, on obtient un code qui ressemble à ceci :

Dans les faits, il est rare d'avoir la bonne surprise d'obtenir un code qui n'ait pas à être nettoyé.
© Jean-Pierre Depétris, octobre 2009
Copyleft : cette oeuvre est libre, vous pouvez la redistribuer et/ou la
modifier selon les termes de la Licence Art Libre. Vous trouverez un
exemplaire de cette Licence sur le site Copyleft Attitude
http://www.artlibre.org/
ainsi que sur d'autres sites.